Group By
Group By로 테이블에서 가져온 데이터를 몇 개의 그룹으로 분리할 수 있다.

학생들의 성적의 평균을 과제 유형에 따라 나누어 보고싶다고 하자.
GradeType을 기준으로 그룹을 묶어주어야 하기때문에 GROUP BY GradeType으로 그룹핑을 해줄 수 있다.
다만 여기서 문제점은 NULL값은 평균값을 구할 때 무시된다는 점이다.
만약 여기서 NULL값을 0점처리 하고싶다면 AVG(Group)을 AVG(ISNULL(Grade, 0))로 계산해야한다.
여기서 한단계 더 나아가보자.
Group By로 각 학생들의 퀴즈와 시험점수 평균을 내어보자.
이때는 Group By에 복수의 열을 넣어주면 된다.

학생 - 시험 유형 - 평균 점수 형태로 바꾸어주었다.
여기서 시험 평균 점수가 70점 이상인 학생의 데이터만 보고싶다고 하자.
이 경우에는 Having을 이용할 수 있다.
HAVING
Having과 Where은 선택 기준을 적용할때 이용된다.
다만 Where는 각 행에 적용되는 기준이라면 Having은 그룹 차원으로 선택 논리를 적용시킨다.
(where를 쓸때는 집계함수같은걸 못쓴다 avg, count, sum...)

Having 키워드는 반드시 group by 뒤와 order by 앞에 와야한다.
이번에는 7학년이면 70점 이상, 8학년이면 75점 이상인 학생 목록을 뽑아볼것이다.
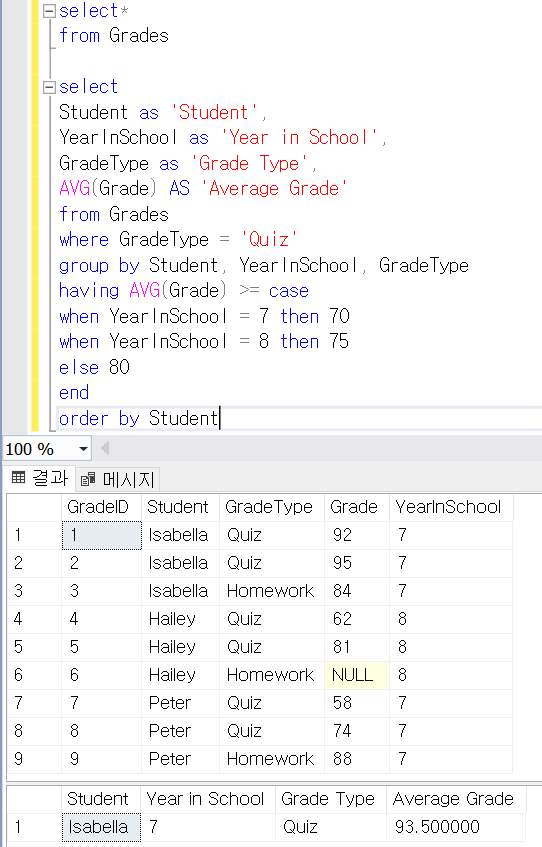
위처럼 case문을 이용해 다른 조건을 부여할 수 있다.
GROUP BY와 CASE
Group By에서 case 표현이 사용될 때, 그와 똑같은 표현이 select의 문장에서도 사용되어야한다.

이와 같이 Select와 Group By에 같은 case문장이 사용되어야한다.







